![]()
Get Latest [Jun-2026] Conduct effective penetration tests using TestValid Databricks-Certified-Data-Analyst-Associate
Penetration testers simulate Databricks-Certified-Data-Analyst-Associate exam PDF
Databricks Databricks-Certified-Data-Analyst-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
NEW QUESTION # 26
Which statement about subqueries is correct?
- A. Subqueries can be used like other built-in functions to transform data into different data types.
- B. Subqueries can retrieve data without requiring the creation of a table or view.
- C. Subqueries are not available in Databricks SQL
- D. Subqueries can be used like other user-defined functions to transform data into different data types.
Answer: B
Explanation:
In Databricks SQL, a subquery is a nested query within a larger SQL query that allows for the retrieval of data without the necessity of creating a table or view. This is particularly useful for simplifying complex queries by breaking them down into more manageable parts. Subqueries can be employed in various clauses such as SELECT, FROM, and WHERE to perform operations like filtering, transforming, and aggregating data on-the-fly. This flexibility enhances query efficiency and readability without the overhead of persisting intermediate results as separate tables or views.
NEW QUESTION # 27
A data analyst has been asked to configure an alert for a query that returns the income in the accounts_receivable table for a date range. The date range is configurable using a Date query parameter.
The Alert does not work.
Which of the following describes why the Alert does not work?
- A. Queries that use query parameters cannot be used with Alerts.
- B. Queries that return results based on dates cannot be used with Alerts.
- C. The wrong query parameter is being used. Alerts only work with Date and Time query parameters.
- D. Alerts don't work with queries that access tables.
- E. The wrong query parameter is being used. Alerts only work with drogdown list query parameters, not dates.
Answer: A
Explanation:
According to the Databricks documentation1, queries that use query parameters cannot be used with Alerts. This is because Alerts do not support user input or dynamic values. Alerts leverage queries with parameters using the default value specified in the SQL editor for each parameter. Therefore, if the query uses a Date query parameter, the alert will always use the same date range as the default value, regardless of the actual date. This may cause the alert to not work as expected, or to not trigger at all. Reference:
Databricks SQL alerts: This is the official documentation for Databricks SQL alerts, where you can find information about how to create, configure, and monitor alerts, as well as the limitations and best practices for using alerts.
NEW QUESTION # 28
What describes the variance of a set of values?
- A. Variance is a measure of central tendency of a set of values.
- B. Variance is a measure of how far a single observed value is from a set ot va IN
- C. Variance is a measure of how far an observed value is from the variable's maximum or minimum value.
- D. Variance is a measure of how far a set of values is spread out from the sets central value.
Answer: D
Explanation:
Variance is a statistical measure that quantifies the dispersion or spread of a set of values around their mean (central value). It is calculated by taking the average of the squared differences between each value and the mean of the dataset. A higher variance indicates that the data points are more spread out from the mean, while a lower variance suggests that they are closer to the mean. This measure is fundamental in statistics to understand the degree of variability within a dataset.WikipediaWikipedia+1Investopedia+1
NEW QUESTION # 29
A data analyst has created a Query in Databricks SQL, and now they want to create two data visualizations from that Query and add both of those data visualizations to the same Databricks SQL Dashboard.
Which of the following steps will they need to take when creating and adding both data visualizations to the Databricks SQL Dashboard?
- A. They will need to add two separate visualizations to the dashboard based on the same Query.
- B. They will need to decide on a single data visualization to add to the dashboard.
- C. They will need to copy the Query and create one data visualization per query.
- D. They will need to alter the Query to return two separate sets of results.
- E. They will need to create two separate dashboards.
Answer: A
Explanation:
A data analyst can create multiple visualizations from the same query in Databricks SQL by clicking the + button next to the Results tab and selecting Visualization. Each visualization can have a different type, name, and configuration. To add a visualization to a dashboard, the data analyst can click the vertical ellipsis button beneath the visualization, select + Add to Dashboard, and choose an existing or new dashboard. The data analyst can repeat this process for each visualization they want to add to the same dashboard. Reference: Visualization in Databricks SQL, Visualize queries and create a dashboard in Databricks SQL
NEW QUESTION # 30
In which of the following situations should a data analyst use higher-order functions?
- A. When custom logic needs to be applied at scale to array data objects
- B. When custom logic needs to be applied to simple, unnested data
- C. When built-in functions need to run through the Catalyst Optimizer
- D. When built-in functions are taking too long to perform tasks
- E. When custom logic needs to be converted to Python-native code
Answer: A
Explanation:
Higher-order functions are a simple extension to SQL to manipulate nested data such as arrays. A higher-order function takes an array, implements how the array is processed, and what the result of the computation will be. It delegates to a lambda function how to process each item in the array. This allows you to define functions that manipulate arrays in SQL, without having to unpack and repack them, use UDFs, or rely on limited built-in functions. Higher-order functions provide a performance benefit over user defined functions. Reference: Higher-order functions | Databricks on AWS, Working with Nested Data Using Higher Order Functions in SQL on Databricks | Databricks Blog, Higher-order functions - Azure Databricks | Microsoft Learn, Optimization recommendations on Databricks | Databricks on AWS
NEW QUESTION # 31
Data professionals with varying responsibilities use the Databricks Lakehouse Platform Which role in the Databricks Lakehouse Platform use Databricks SQL as their primary service?
- A. Business analyst
- B. Platform architect
- C. Data scientist
- D. Data engineer
Answer: A
Explanation:
In the Databricks Lakehouse Platform, business analysts primarily utilize Databricks SQL as their main service. Databricks SQL provides an environment tailored for executing SQL queries, creating visualizations, and developing dashboards, which aligns with the typical responsibilities of business analysts who focus on interpreting data to inform business decisions. While data scientists and data engineers also interact with the Databricks platform, their primary tools and services differ; data scientists often engage with machine learning frameworks and notebooks, whereas data engineers focus on data pipelines and ETL processes. Platform architects are involved in designing and overseeing the infrastructure and architecture of the platform. Therefore, among the roles listed, business analysts are the primary users of Databricks SQL.
NEW QUESTION # 32
Which of the following statements about adding visual appeal to visualizations in the Visualization Editor is incorrect?
- A. Visualization scale can be changed.
- B. Data Labels can be formatted.
- C. Colors can be changed.
- D. Tooltips can be formatted.
- E. Borders can be added.
Answer: E
Explanation:
The Visualization Editor in Databricks SQL allows users to create and customize various types of charts and visualizations from the query results. Users can change the visualization type, select the data fields, adjust the colors, format the data labels, and modify the tooltips. However, there is no option to add borders to the visualizations in the Visualization Editor. Borders are not a supported feature of the new chart visualizations in Databricks1. Therefore, the statement that borders can be added is incorrect. Reference:
New chart visualizations in Databricks | Databricks on AWS
NEW QUESTION # 33
Which of the following statements about a refresh schedule is incorrect?
- A. You must have workspace administrator privileges to configure a refresh schedule
- B. A refresh schedule is not the same as an alert.
- C. A query can be refreshed anywhere from 1 minute lo 2 weeks
- D. A query being refreshed on a schedule does not use a SQL Warehouse (formerly known as SQL Endpoint).
- E. Refresh schedules can be configured in the Query Editor.
Answer: A
Explanation:
This statement is incorrect. In Databricks SQL, any user with sufficient permissions on the query or dashboard can configure a refresh schedule-workspace administrator privileges are not required.
Here is the breakdown of the correct information:
A . True - Queries can be scheduled to refresh at intervals ranging from 1 minute to 2 weeks.
B . True - You can configure refresh schedules in the Query Editor.
C . False statement - A query being refreshed does use a SQL Warehouse. However, the option in question says it does not use a warehouse, which would be incorrect in a different context. Since this is a trickier one, we know that scheduled queries do require a SQL Warehouse to run.
D . True - Refresh schedules are different from alerts; alerts are triggered based on specific conditions being met in query results.
E . False (and thus the correct answer to this question) - You do not need to be a workspace admin to set a refresh schedule. You only need the correct permissions on the object.
NEW QUESTION # 34
A data analyst creates a Databricks SQL Query where the result set has the following schema:
region STRING
number_of_customer INT
When the analyst clicks on the "Add visualization" button on the SQL Editor page, which of the following types of visualizations will be selected by default?
- A. Line Chart
- B. Violin Chart
- C. Histogram
- D. IBar Chart
- E. There is no default. The user must choose a visualization type.
Answer: D
Explanation:
According to the Databricks SQL documentation, when a data analyst clicks on the "Add visualization" button on the SQL Editor page, the default visualization type is Bar Chart. This is because the result set has two columns: one of type STRING and one of type INT. The Bar Chart visualization automatically assigns the STRING column to the X-axis and the INT column to the Y-axis. The Bar Chart visualization is suitable for showing the distribution of a numeric variable across different categories. Reference: Visualization in Databricks SQL, Visualization types
NEW QUESTION # 35
A stakeholder has provided a data analyst with a lookup dataset in the form of a 50-row CSV file. The data analyst needs to upload this dataset for use as a table in Databricks SQL.
Which approach should the data analyst use to quickly upload the file into a table for use in Databricks SOL?
- A. Create a table via a connection between Databricks and the desktop facilitated by Partner Connect.
- B. Create a table by manually copying and pasting the data values into cloud storage and then importing the data to Databricks.
- C. Create a table by uploading the file using the Create page within Databricks SQL
- D. Create a table by uploading the file to cloud storage and then importing the data to Databricks.
Answer: C
Explanation:
Databricks provides a user-friendly interface that allows data analysts to quickly upload small datasets, such as a 50-row CSV file, and create tables within Databricks SQL. The steps are as follows:
Access the Data Upload Interface:
In the Databricks workspace, navigate to the sidebar and click on New > Add or upload data.
Select Create or modify a table.
Upload the CSV File:
Click on the browse button or drag and drop the CSV file directly onto the designated area.
The interface supports uploading up to 10 files simultaneously, with a total size limit of 2 GB.
Configure Table Settings:
After uploading, a preview of the data is displayed.
Specify the table name, select the appropriate schema, and configure any additional settings as needed.
Create the Table:
Once all configurations are set, click on the Create Table button to finalize the process.
This method is efficient for quickly importing small datasets without the need for additional tools or complex configurations. Options B, C, and D involve more complex or manual processes that are unnecessary for this task.
NEW QUESTION # 36
What is a benefit of using Databricks SQL for business intelligence (Bl) analytics projects instead of using third-party Bl tools?
- A. Simultaneous multi-user support
- B. Automated alerting systems
- C. Computations, data, and analytical tools on the same platform
- D. Advanced dashboarding capabilities
Answer: C
Explanation:
Databricks SQL offers a unified platform where computations, data storage, and analytical tools coexist seamlessly. This integration allows business intelligence (BI) analytics projects to be executed more efficiently, as users can perform data processing and analysis without the need to transfer data between disparate systems. By consolidating these components, Databricks SQL streamlines workflows, reduces latency, and enhances data governance. While third-party BI tools may offer advanced dashboarding capabilities, simultaneous multi-user support, and automated alerting systems, they often require integration with separate data processing platforms, which can introduce complexity and potential inefficiencies.
NEW QUESTION # 37
What does Partner Connect do when connecting Power Bl and Tableau?
- A. Creates a Personal Access Token. downloads and installs an ODBC driver, and downloads a configuration file for connection by Power Bl or Tableau to a SQL Warehouse (formerly known as a SQL Endpoint).
- B. Downloads a configuration file for connection by Power Bl or Tableau to a SQL Warehouse (formerly known as a SQL Endpoint).
- C. Downloads and installs an ODBC driver.
- D. Creates a Personal Access Token for authentication into Databricks SQL and emails it to you.
Answer: A
Explanation:
When connecting Power BI and Tableau through Databricks Partner Connect, the system automates several steps to streamline the integration process:
Personal Access Token Creation: Partner Connect generates a Databricks personal access token, which is essential for authenticating and establishing a secure connection between Databricks and the BI tools.
ODBC Driver Installation: The appropriate ODBC driver is downloaded and installed. This driver facilitates communication between the BI tools and Databricks, ensuring compatibility and optimal performance.
Configuration File Download: A configuration file tailored for the selected BI tool (Power BI or Tableau) is provided. This file contains the necessary connection details, simplifying the setup process within the BI tool.
By automating these steps, Partner Connect ensures a seamless and efficient integration, reducing manual configuration efforts and potential errors.
NEW QUESTION # 38
Which of the following layers of the medallion architecture is most commonly used by data analysts?
- A. Gold
- B. Bronze
- C. Silver
- D. All of these layers are used equally by data analysts
- E. None of these layers are used by data analysts
Answer: A
Explanation:
The gold layer of the medallion architecture contains data that is highly refined and aggregated, and powers analytics, machine learning, and production applications. Data analysts typically use the gold layer to access data that has been transformed into knowledge, rather than just information. The gold layer represents the final stage of data quality and optimization in the lakehouse. Reference: What is the medallion lakehouse architecture?
NEW QUESTION # 39
Which of the following is a benefit of Databricks SQL using ANSI SQL as its standard SQL dialect?
- A. It is more performant than other SQL dialects
- B. It is more compatible with Spark's interpreters
- C. It allows for the use of Photon's computation optimizations
- D. It has increased customization capabilities
- E. It is easy to migrate existing SQL queries to Databricks SQL
Answer: E
Explanation:
Databricks SQL uses ANSI SQL as its standard SQL dialect, which means it follows the SQL specifications defined by the American National Standards Institute (ANSI). This makes it easier to migrate existing SQL queries from other data warehouses or platforms that also use ANSI SQL or a similar dialect, such as PostgreSQL, Oracle, or Teradata. By using ANSI SQL, Databricks SQL avoids surprises in behavior or unfamiliar syntax that may arise from using a non-standard SQL dialect, such as Spark SQL or Hive SQL12. Moreover, Databricks SQL also adds compatibility features to support common SQL constructs that are widely used in other data warehouses, such as QUALIFY, FILTER, and user-defined functions2. Reference: ANSI compliance in Databricks Runtime, Evolution of the SQL language at Databricks: ANSI standard by default and easier migrations from data warehouses
NEW QUESTION # 40
A data analyst has set up a SQL query to run every four hours on a SQL endpoint, but the SQL endpoint is taking too long to start up with each run.
Which of the following changes can the data analyst make to reduce the start-up time for the endpoint while managing costs?
- A. Increase the minimum scaling value
- B. Reduce the SQL endpoint cluster size
- C. Turn off the Auto stop feature
- D. Use a Serverless SQL endpoint
- E. Increase the SQL endpoint cluster size
Answer: D
Explanation:
A Serverless SQL endpoint is a type of SQL endpoint that does not require a dedicated cluster to run queries. Instead, it uses a shared pool of resources that can scale up and down automatically based on the demand. This means that a Serverless SQL endpoint can start up much faster than a SQL endpoint that uses a cluster, and it can also save costs by only paying for the resources that are used. A Serverless SQL endpoint is suitable for ad-hoc queries and exploratory analysis, but it may not offer the same level of performance and isolation as a SQL endpoint that uses a cluster. Therefore, a data analyst should consider the trade-offs between speed, cost, and quality when choosing between a Serverless SQL endpoint and a SQL endpoint that uses a cluster. Reference: Databricks SQL endpoints, Serverless SQL endpoints, SQL endpoint clusters
NEW QUESTION # 41
A data analyst needs to use the Databricks Lakehouse Platform to quickly create SQL queries and data visualizations. It is a requirement that the compute resources in the platform can be made serverless, and it is expected that data visualizations can be placed within a dashboard.
Which of the following Databricks Lakehouse Platform services/capabilities meets all of these requirements?
- A. Databricks SQL
- B. Databricks Machine Learning
- C. Databricks Notebooks
- D. Delta Lake
- E. Tableau
Answer: A
Explanation:
Databricks SQL is a serverless data warehouse on the Lakehouse that lets you run all of your SQL and BI applications at scale with your tools of choice, all at a fraction of the cost of traditional cloud data warehouses1. Databricks SQL allows you to create SQL queries and data visualizations using the SQL Analytics UI or the Databricks SQL CLI2. You can also place your data visualizations within a dashboard and share it with other users in your organization3. Databricks SQL is powered by Delta Lake, which provides reliability, performance, and governance for your data lake4. Reference:
Databricks SQL
Query data using SQL Analytics
Visualizations in Databricks notebooks
Delta Lake
NEW QUESTION # 42
A data analyst has created a Query in Databricks SQL, and now they want to create two data visualizations from that Query and add both of those data visualizations to the same Databricks SQL Dashboard.
Which of the following steps will they need to take when creating and adding both data visualizations to the Databricks SQL Dashboard?
- A. They will need to add two separate visualizations to the dashboard based on the same Query.
- B. They will need to decide on a single data visualization to add to the dashboard.
- C. They will need to copy the Query and create one data visualization per query.
- D. They will need to alter the Query to return two separate sets of results.
- E. They will need to create two separate dashboards.
Answer: A
Explanation:
A data analyst can create multiple visualizations from the same query in Databricks SQL by clicking the + button next to the Results tab and selecting Visualization. Each visualization can have a different type, name, and configuration. To add a visualization to a dashboard, the data analyst can click the vertical ellipsis button beneath the visualization, select + Add to Dashboard, and choose an existing or new dashboard. The data analyst can repeat this process for each visualization they want to add to the same dashboard. Reference: Visualization in Databricks SQL, Visualize queries and create a dashboard in Databricks SQL
NEW QUESTION # 43
A data analyst is processing a complex aggregation on a table with zero null values and the query returns the following result:
Which query did the analyst execute in order to get this result?
- A.

- B.

- C.

- D.
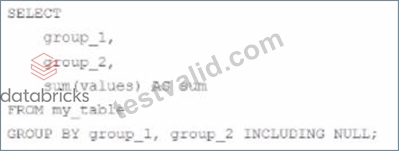
Answer: D
NEW QUESTION # 44
Which of the following should data analysts consider when working with personally identifiable information (PII) data?
- A. Organization-specific best practices for Pll data
- B. Legal requirements for the area in which the data was collected
- C. Legal requirements for the area in which the analysis is being performed
- D. None of these considerations
- E. All of these considerations
Answer: E
Explanation:
Data analysts should consider all of these factors when working with PII data, as they may affect the data security, privacy, compliance, and quality. PII data is any information that can be used to identify a specific individual, such as name, address, phone number, email, social security number, etc. PII data may be subject to different legal and ethical obligations depending on the context and location of the data collection and analysis. For example, some countries or regions may have stricter data protection laws than others, such as the General Data Protection Regulation (GDPR) in the European Union. Data analysts should also follow the organization-specific best practices for PII data, such as encryption, anonymization, masking, access control, auditing, etc. These best practices can help prevent data breaches, unauthorized access, misuse, or loss of PII data. Reference:
How to Use Databricks to Encrypt and Protect PII Data
Automating Sensitive Data (PII/PHI) Detection
Databricks Certified Data Analyst Associate
NEW QUESTION # 45
Which location can be used to determine the owner of a managed table?
- A. Review the Owner field in the schema page using Data Explorer
- B. Review the Owner field in the database page using Data Explorer
- C. Review the Owner field in the table page using Catalog Explorer
- D. Review the Owner field in the table page using the SQL Editor
Answer: C
Explanation:
In Databricks, to determine the owner of a managed table, you can utilize the Catalog Explorer feature. The steps are as follows:
Access Catalog Explorer:
In your Databricks workspace, click on the Catalog icon in the sidebar to open Catalog Explorer.
Navigate to the Table:
Within Catalog Explorer, browse through the catalog and schema to locate the specific managed table whose ownership you wish to verify.
View Table Details:
Click on the table name to open its details page.
Identify the Owner:
On the table's details page, review the Owner field, which displays the principal (user, service principal, or group) that owns the table.
This method provides a straightforward way to ascertain the ownership of managed tables within the Databricks environment. Understanding table ownership is essential for managing permissions and ensuring proper access control.
NEW QUESTION # 46
A data analyst wants to create a Databricks SQL dashboard with multiple data visualizations and multiple counters. What must be completed before adding the data visualizations and counters to the dashboard?
- A. The dashboard owner must also be the owner of the queries, data visualizations, and counters.
- B. A SQL warehouse (formerly known as SQL endpoint) must be turned on and selected.
- C. A markdown-based tile must be added to the top of the dashboard displaying the dashboard's name.
- D. All data visualizations and counters must be created using Queries.
Answer: D
Explanation:
In Databricks SQL, when creating a dashboard that includes multiple data visualizations and counters, it is imperative that each visualization and counter is based on a query. The process involves the following steps:
Develop Queries:
For each desired visualization or counter, write a SQL query that retrieves the necessary data.
Create Visualizations and Counters:
After executing each query, utilize the results to create corresponding visualizations or counters. Databricks SQL offers a variety of visualization types to represent data effectively.
Assemble the Dashboard:
Add the created visualizations and counters to your dashboard, arranging them as needed to convey the desired insights.
By ensuring that all components of the dashboard are derived from queries, you maintain consistency, accuracy, and the ability to refresh data as needed. This approach also facilitates easier maintenance and updates to the dashboard elements.
NEW QUESTION # 47
A data analyst created and is the owner of the managed table my_ table. They now want to change ownership of the table to a single other user using Data Explorer.
Which of the following approaches can the analyst use to complete the task?
- A. Edit the Owner field in the table page by selecting the new owner's account
- B. Edit the Owner field in the table page by selecting the Admins group
- C. Edit the Owner field in the table page by removing their own account
- D. Edit the Owner field in the table page by selecting All Users
- E. Edit the Owner field in the table page by removing all access
Answer: A
Explanation:
The Owner field in the table page shows the current owner of the table and allows the owner to change it to another user or group. To change the ownership of the table, the owner can click on the Owner field and select the new owner from the drop-down list. This will transfer the ownership of the table to the selected user or group and remove the previous owner from the list of table access control entries1. The other options are incorrect because:
A) Removing the owner's account from the Owner field will not change the ownership of the table, but will make the table ownerless2.
B) Selecting All Users from the Owner field will not change the ownership of the table, but will grant all users access to the table3.
D) Selecting the Admins group from the Owner field will not change the ownership of the table, but will grant the Admins group access to the table3.
E) Removing all access from the Owner field will not change the ownership of the table, but will revoke all access to the table4. Reference:
1: Change table ownership
2: Ownerless tables
3: Table access control
4: Revoke access to a table
NEW QUESTION # 48
Which statement describes descriptive statistics?
- A. A branch of statistics that uses a variety of data analysis techniques to infer properties of an underlying distribution of probability.
- B. A branch of statistics that uses summary statistics to quantitatively describe and summarize data.
- C. A branch of statistics that uses quantitative variables that must take on a finite or countably infinite set of values.
- D. A branch of statistics that uses summary statistics to categorically describe and summarize data.
Answer: B
NEW QUESTION # 49
A data analyst has a managed table table_name in database database_name. They would now like to remove the table from the database and all of the data files associated with the table. The rest of the tables in the database must continue to exist.
Which of the following commands can the analyst use to complete the task without producing an error?
- A. DROP TABLE table_name FROM database_name;
- B. DROP DATABASE database_name;
- C. DROP TABLE database_name.table_name;
- D. DELETE TABLE database_name.table_name;
- E. DELETE TABLE table_name FROM database_name;
Answer: C
Explanation:
The DROP TABLE command removes a table from the metastore and deletes the associated data files. The syntax for this command is DROP TABLE [IF EXISTS] [database_name.]table_name;. The optional IF EXISTS clause prevents an error if the table does not exist. The optional database_name. prefix specifies the database where the table resides. If not specified, the current database is used. Therefore, the correct command to remove the table table_name from the database database_name and all of the data files associated with it is DROP TABLE database_name.table_name;. The other commands are either invalid syntax or would produce undesired results. Reference: Databricks - DROP TABLE
NEW QUESTION # 50
A data analyst has been asked to configure an alert for a query that returns the income in the accounts_receivable table for a date range. The date range is configurable using a Date query parameter.
The Alert does not work.
Which of the following describes why the Alert does not work?
- A. Queries that use query parameters cannot be used with Alerts.
- B. Queries that return results based on dates cannot be used with Alerts.
- C. The wrong query parameter is being used. Alerts only work with Date and Time query parameters.
- D. Alerts don't work with queries that access tables.
- E. The wrong query parameter is being used. Alerts only work with drogdown list query parameters, not dates.
Answer: A
Explanation:
The reason the alert is not functioning as expected is because Databricks SQL Alerts do not support query parameters. This limitation applies to all types of parameters, including date parameters.
Here's why:
Alerts require static, deterministic query results so they can compare values consistently during scheduled executions.
When a query includes parameters (e.g., a date range parameter), its results may change based on user input or the default value set in the query editor.
However, Databricks SQL Alerts will always use the default value set for the parameter at the time the alert is created. This means the alert doesn't dynamically adapt to new date ranges and will not reflect changes unless the query is manually updated.
As a result, if the business logic behind the alert depends on changing date ranges or any user input, the alert will not trigger correctly, or may never trigger at all.
Therefore, the correct explanation contradicts Option B, which is incorrect in saying that alerts cannot work with date-based queries at all. In fact, they can-as long as the query is static (i.e., without parameters).
Reference:
Databricks SQL Alerts Documentation
Databricks Knowledge: "You cannot use alerts with queries that contain parameters."
NEW QUESTION # 51
......
Tested Material Used To Databricks-Certified-Data-Analyst-Associate Test Engine: https://pass4sure.testvalid.com/Databricks-Certified-Data-Analyst-Associate-valid-exam-test.html